High-Frequency Settlement Engine
C / Go / PostgreSQL / Docker / Protobufs
A miniature exchange backend split into two processes: a matching engine in C that fills orders in memory, and a settlement gateway in Go that records the resulting trades and balances in PostgreSQL. The exercise is to push order throughput as high as possible without giving up ACID correctness in the ledger.
Execution Architecture
Load is generated by an LFSR-driven random-walk simulator in the gateway that submits an order every 10µs; the engineering problem is keeping the matching path deterministic and the ledger ACID-compliant at that rate.

The system architecture decouples low-latency matching from high-integrity settlement. The execution core is implemented in C to maintain deterministic sub-millisecond response times. The book itself is a flat array of 100,000 price levels, each holding a FIFO queue of resting orders (price-time priority), with best-bid/best-ask cursors so the matching loop walks price levels directly instead of chasing a tree. To eliminate jitter caused by malloc() syscalls and heap fragmentation, order nodes come from a custom slab allocator: at startup the engine pre-allocates a contiguous pool of two million nodes and manages it with a LIFO pointer stack, giving O(1) allocation and deallocation. Because the stack is LIFO, recently freed nodes are reused first, keeping the matching loop's working set hot in the CPU cache.
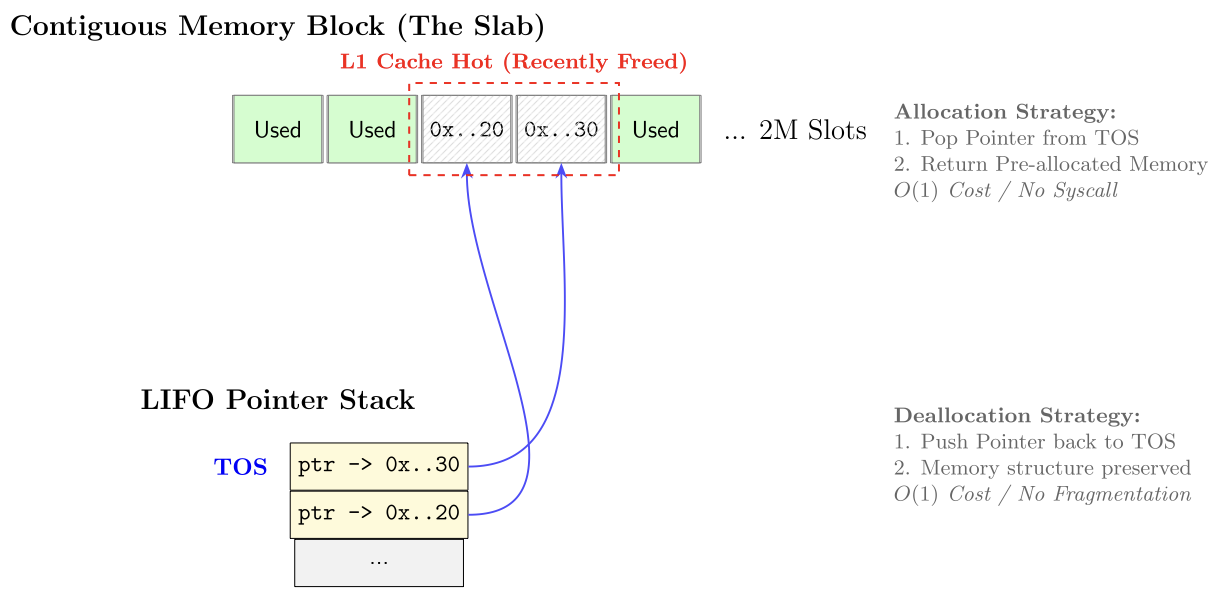
Persistence & ACID Compliance
The settlement gateway, written in Go, bridges the execution engine to a PostgreSQL ledger. Execution reports stream into a buffered channel, and a settlement worker flushes every 1,000 trades or every 10ms, whichever comes first. Each flush first nets the balance deltas per user in memory, then commits a single ACID transaction containing the aggregated balance updates and a COPY-protocol bulk insert of the raw trades into the ledger table. This collapses thousands of per-trade fsync() calls into one Write-Ahead Log flush per batch, which keeps WAL write amplification manageable during high-throughput bursts (10k+ TPS) without giving up atomicity or durability.
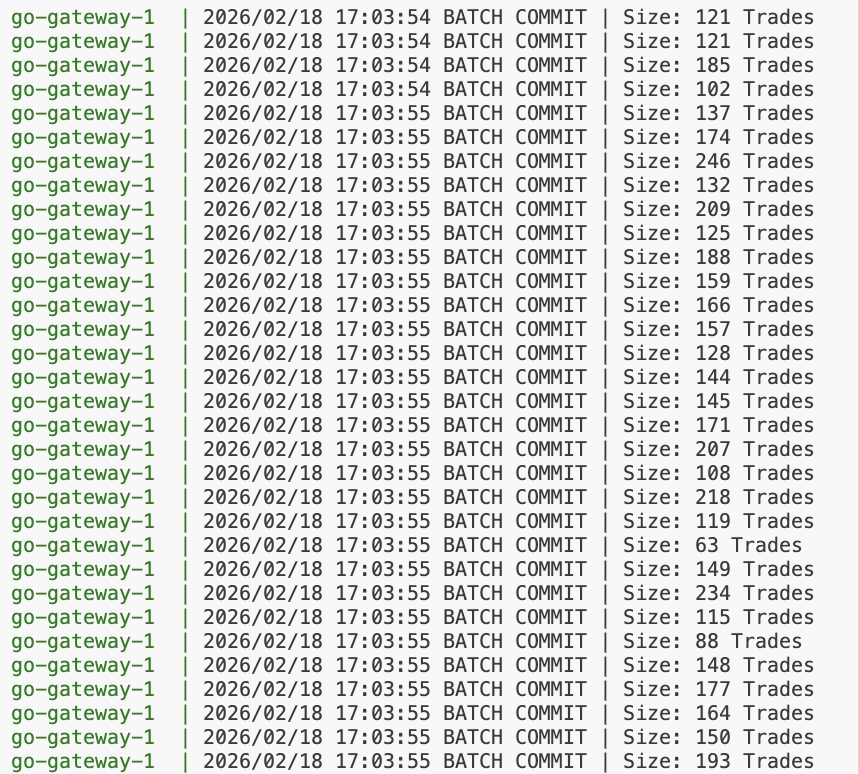
COPY protocol. The variance in batch size is because of the randomization employed in the ingress engine, meaning not all orders immediately have a match. This reduces disk I/O operations by up to three orders of magnitude while maintaining durability guarantees.
Data serialization is handled via Protocol Buffers. We define a strict schema using uint64 and uint32 types to enforce fixed-point arithmetic, preventing floating-point errors which are not allowed in financial software. The entire stack is orchestrated via Docker Compose, utilizing named volumes to bypass the virtiofs limitation on Unix Domain Sockets within macOS environments.