Election Sentiment Analysis
Python / Scikit-learn / NLTK / Snscrape
NB: project done in Fall 2022, X (renamed from Twitter) has overhauled their API and this project, particularly the ETL phase, would have been done differently today.
A Naive Bayes sentiment model applied to scraped tweets from the 2016 US election cycle, testing whether aggregate Twitter sentiment predicts electoral outcomes. Scored against the actual results, it called both the party primaries and the general election correctly.
ETL & Preprocessing Pipeline
The pipeline forecasts 2016 election results using a full Extract-Transform-Load (ETL) process. We used Snscrape to harvest a large corpus of political tweets associated with the primary candidates (Clinton, Trump, Sanders, Bush), bypassing standard API limits. Extraction ran as automated CLI queries bounded to the election cycle (2016-01-01 to 2016-11-08) so post-election content could not contaminate the data. The scraper targeted official candidate handles (like @realDonaldTrump) and streamed payloads into JSONL files, preserving metadata for downstream analysis such as per-candidate sentiment over time.
Raw text required cleaning to be viable. We implemented a preprocessing chain using Regex and NLTK to normalize the dataset. This involved stripping URLs, removing user tags, normalizing repeated characters (e.g., "cooooooool" → "cool"), and filtering out standard English stopwords to reduce feature noise.
def preprocess(input_df): # Normalize case out = input_df.apply(lambda x: x.lower()) # Remove Regex patterns (URLs, Mentions) out = out.apply(lambda x: clean_URLs(x)) out = out.apply(lambda x: clean_tags(x)) # Normalize repetition (e.g. "Runnnnn" -> "Run") out = out.apply(lambda x: clean_repetition(x)) # Remove NLTK stopwords out = out.apply(lambda x: clean_stopwords(x)) return out
Naive Bayes Classification
We utilized the Sentiment140 dataset to train our classifier. The text data was vectorized using a Binary Count Vectorizer, effectively creating a Bag-of-Words model that ignores frequency and position but tracks presence. We selected a Multinomial Naive Bayes classifier. Despite the "naive" assumption of feature independence, this probabilistic model empirically excels at high-dimensional text classification.
Visualizing the training data reveals distinct lexical patterns between classes. The word clouds below illustrate the most frequent tokens associated with negative and positive sentiment in the Sentiment140 dataset, serving as the basis for the model's probability distribution.
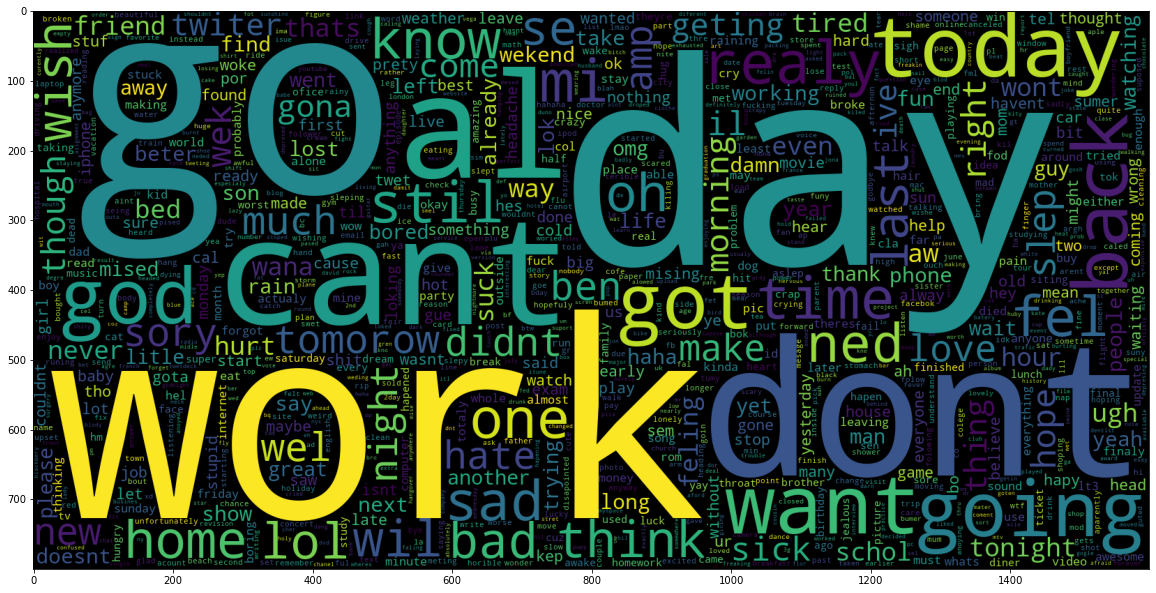
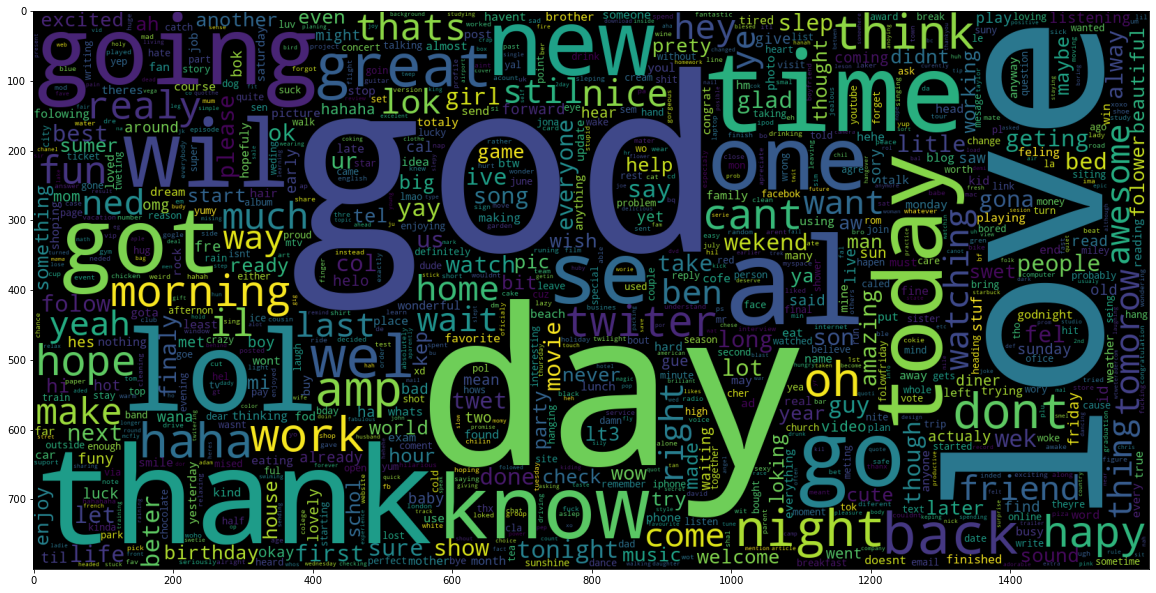
We trained the model on a standard 80/20 train-test split, achieving an accuracy score of 77.7% on the validation set. We did not do hyperparameter tuning.
# Pipeline Definition nb_model = make_pipeline( CountVectorizer(binary=True), MultinomialNB() ) # Training nb_model.fit(train_text, train_target) model_score = nb_model.score(test_text, test_target) print(f"Validation Accuracy: {model_score}") # Output: 0.77705625
Results & Thresholding
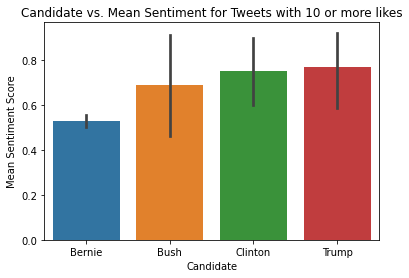
To improve signal quality, we applied an activity threshold, filtering for tweets with >10 likes. Filtering for engagement widened the mean sentiment separation between candidates, supporting the hypothesis that high-engagement content better reflects voter intent than low-quality spam.
Quantitatively, the model successfully predicted the outcomes of both the Primaries and the General Election. In the GOP primary, Trump (0.769) led Bush (0.687). In the Democratic primary, Clinton (0.750) led Sanders (0.526). Most notably for the General Election, despite close polling data at the time, the model's engagement-weighted sentiment favored Trump (0.769) over Clinton (0.750), aligning with the final Electoral College result.